


Inserting DataFrames into BigQuery as fast as possible
Some of the easiest to use BigQuery APIs have ridiculously low quota limits. If you're like me and looking for a way out, read on.

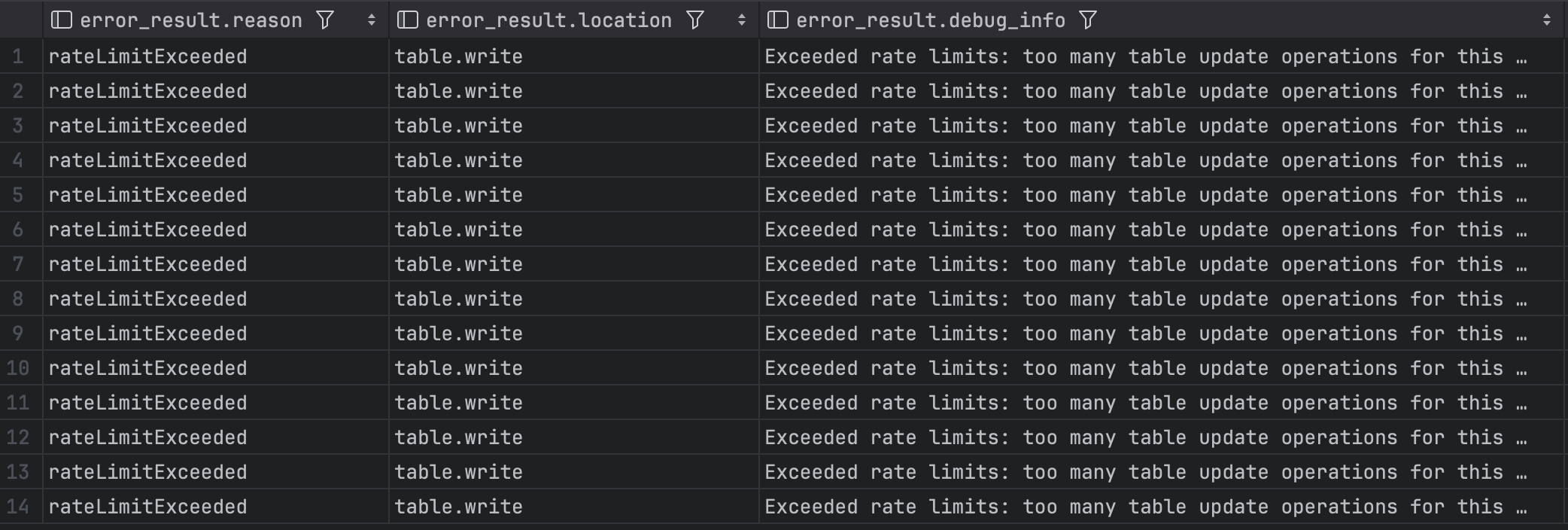
This is a problem I ran into while building my company MOZR. We build data pipelines for great companies and need to insert a lot of data into BigQuery. This article is going to be very nerdy and serves as a solution to bookmark for others bumping into the BigQuery insert quota limits.
One more thing to call out before jumping in is that historically, building data pipelines has been about proving something out with transformations in a jupyter notebook and then handing it over to some other team who rewrites it a different language in a scalable way and to be honest, that sucks. My goal for this is to take a single pandas data frame and insert it into BQ. In other words, when I’m to the point where I’m ready to insert data, I’ve already had data chunked into files, or the files are small enough to run in a large spot instance.
The easy way
Baked into pandas is a helper method df.to_gbq which you can use to insert data into a BQ table with the standard if_exists options you’d expect (replace, append, or fail). This is wrapping the BQ tables.insert api. When you insert data this way to a standard table, BigQuery allows you to insert 5 times every 10 seconds (0.5 operations per second). When I read that, I found it insanely limiting. You can get this a little bit higher if you’re using a partitioned table (which you honestly should be) but that only gets you 50 operations every 10 seconds (around 5 operations per second).
df.to_gbq(
destination_table="my_dataset.my_table",
project="my_project",
if_exists="append"
)Be mindful too that there is a flag on to_gbq to chunk your DF into smaller sections, but in my experience we’ve never hit a “this is too big” error and I can’t find a size limit on tables.insert. I’m sure there is a limit but it inherits from some other standard SQL function. All to say, only touch this if you’re getting push back from BigQuery and then be super careful because when you chunk and insert, it will invoke multiple calls to this already very limited API, and each call is not transactional. If it fails while inserting one of the chunks, it won’t be rolled back.
While these rate limits are extremely low, if you’re batching data like we often do, you can probably operate within these limits. But, if you’re also tired of seeing rate limit errors from BigQuery when using tables.insert, it might be time for a faster solution.
The faster way
The faster way to insert data into BigQuery is using what they call their legacy streaming API. The name of the api is tabledata.insertAll and even though it has streaming in the name, it can be used for batch inserts (like a panda data frame).
How much faster is the legacy streaming API? You can reference the streaming insert quotas since they may change over time. They currently read 1GB per per project in the US and EU regions. This is much much better.
The only downside is you need to be very careful about how you insert your data. Each insertAll request has a limit of 10MB per row and 50,000 rows per request. Additionally, each requests must be no more than 10MB. So, you will almost always be chunking your data using this API. Fortunately, google has a built-in helper library to take a pandas DF and chunk / insert with reasonable defaults.
from google.cloud import bigquery
client = bigquery.Client()
client.insert_rows_from_dataframe(table_id, df)The helper library really use very nice. And btw, while it’s called the “legacy” API, there are no plans to deprecate or remove it. We’re safe to use it for years to come. However, there are some drawbacks. I already called out that we need to chunk data into requests of 10MB or less. Well, if you’re chunking through your data and all of sudden there is an error around row 2 million, this API is not transactional and therefore, you will need make sure when you retry that chunk of data, you do not insert the previous chunks.
Well, why can’t I just DELETE the contents of the previous job and retry? Well, even though we’re batching data into the streaming API, it still does stream it into the table. Data that was recently appended to the table cannot be touched for a period of time. In my experience this is around an hour.
At MOZR we’ll receive lots of files from customers, many of which are being forwarded from their back-office vendors, who make mistakes. Sometimes those files break because they’re completely wrong and cause pipeline errors, other times they’re incomplete and we won’t find out there was a problem until our customer is checking their data. Either way, they’ll need a quick reprocessing turn-around and I didn’t want to have to fight this pending data cliff on data. (Btw, yes there are a dozen ways you can work around this, like carefully query the most recent version of data for some filename… but these push a lot of complexity downstream and I want my database to be capable).
So, even though there is a wonderful helper library, and there is a much higher rate limit, I just felt like we were interfacing with so many gotchas that I wanted to see what other options we had. And it turns out, there was another, more low level, but also, much much faster BigQuery API that was available.
The fastest (and hardest) way
The last stop on our journey is the BigQuery Storage Write API. This is a very low level protobuf driven API that feels more like you’re working with Kafka than BigQuery. It has the highest quota limits of any other APIs clocking in at 3GB per second for US multi-region (3x more than the legacy streaming API). Feel free to review the current quota limits as they may change over time.
Similar to the legacy streaming API it has a 10MB per request limit, which means we’ll need to chunk our data, but fortunately, the Storage Write API is transactional. Unfortunately, it requires you to define protobuf definitions for every table into which you append data.
At this point it’s worth mentioning that protobuf message names have much stricter requirements than what BigQuery permits via its Flexible Column Names that the previous APIs have allowed you to use. I didn’t realize this limitation until I had built my first prototype. Thankfully, after a few days of back and forth with their support team, I was told there is a work around by setting a field option on the proto message.
Remember, though, I didn’t want to maintain a protobuf schema in addition to a SQL schema for every table (hundreds) in the pipelines we build for our customers. I just wanted to have a convenient way of taking a random dataframe (big or small) and have it “just work.”
This is where things turn hard mode. To achieve my goal of a “just works” utility that could insert an arbitrary dataframe, I needed to implement the following:
Using the schema of the table, dynamically build a protobuf definition for each upload.
Chunk the dataframe into small enough pieces so that we don’t exceed the 10MB per append request limit.
Transactionally commit all changes to the table once we’re done.
Honestly, dynamically creating a protobuf message was the hardest part because you need to venture down the hole of protobuf internals. I felt comfortable doing this because I’ve maintained a protobuf library in the past, but honestly, the codebase is great and fun to splunk though. Here is what we needed to do:
Create a dynamic protobuf descriptor, mapping each dataframe column into a field on the destination table.
Generate a protobuf-friendly name for each column as required and then dynamically add the column_name field option.
Write some helper code so that we turn our python dataframe types into something compatible for BigQuery to then cast into the destination table column’s type. At least it’s very well documented!
I’m not going to embed the code into this article. Instead I’ll share a github gist for you to review with everything there, but it should be pretty obvious that we’re talking about a lot of dense code at this point. I mean, take a look at just the append and commit code to push a single example row: google cloud write a batch docs.
It took me a few hours to end up something that both works and something I’d trust in production. In the end, it looks something like this:
import big_query_storage_write_api as swa
swa.to_gbq(
df=df,
table=internal.BigQueryTable("some_table"),
)I know, it’s really simple. And that’s a good thing. It currently only supports appending data (it won’t create a table automatically), but that would be very simple to add. However, it will take your boring old dataframe, convert it into a protobuf descriptor, align it with the table schema, convert data into chunks, type cast them to match what BigQuery needs, append them to the table, and finally commit them.
This is obviously a very low-level and powerful API. It’s by far the most difficult to use but it’s the least-hard to use incorrectly. I do genuinely sleep better at night knowing that our jobs are transactionally inserting data into tables. And oh, btw! You can immediately delete any appended data if you need to. The Storage Write API does not have the same “not editable while in the streaming window” disadvantage that the legacy insert API does.
From here I think it’s worth developing a polished open source library so that folks can choose from three very simple interfaces that sit on top of increasingly more complex APIs. If someone wants to take this on, reach out to me on Twitter (@film42) and we can collaborate. Otherwise, if you’re patient, I’ll probably just do it myself. If anyone at Google is open to upstreaming this into the BigQuery python client, I would love to make it happen.
Recommendations
There is a significant step up in complexity as you move from tables.insert to tabledata.insertAll and finally to the Streaming Write API. If you feel terrified by the difficulty of maintaining code to support the Streaming Write API and you can work around the limits of the non-transactional streaming API, go for it. It provides a very nice quota that you are unlikely to exceed. It supports flexible columns out of the box, and there are built-in helper methods for JSON and dataframes.
But, if you’re reading this just to understand what your options are, and you’re only occasionally hitting your quota limits using tables.insert (the slow one) and you haven’t tried switching to a partitioned table, do that first. It’s something you can do before this even becomes a problem and depending on your workload, might be good enough.
Finally, if you’re like me and you can’t live with the trade-offs of the legacy streaming API, well, I hope the linked github gist serves you well. And if I’m able to make something easily pip installable, I’ll update this article.