


A Friend-to-Friend Streaming Service
Let's explore building a private streaming service using Plex and IPFS so you and your friends can share content without needing a massive storage array at home.

When Netflix came out, I stropped pirating content. Streaming made my life so much better. I could watch everything I wanted, and it was all above board. Now, though, streaming service companies are popping up every month, building walls around their content library, devaluing the existing subscriptions that I have, all while prices go up. Yuck.
Meanwhile, there are folks beginning to do something about it. Jeff Geerling posted a video making the case for building your own content library for personal use. For about $50 you can buy a Blu-ray player and use it to make digital copies of that pile of DVDs you’ve collected since adolescence. I love seeing folks find a “cheaper” way to watch what they want without sacrificing the convenience of streaming. Although, maybe “cheaper” is a little disingenuous since you’ll need an extra computer and LOT of storage capacity to archive your content.
Maybe you’ve already explored this, or maybe you’re friends with someone who has gone through the effort to build their own Plex or Jellyfin server, found a way to safely expose their media server to the public internet, and give you access. I’m lucky enough to have friends like this. While it sounds ideal, the streaming experience is both incredible and a little disappointing. Watching a movie in 4k Blu-ray blows anything available on Netflix out of the water, but latency (even on fast home internet) and is very noticeable, especially when you scrub through Blu-ray media and the app crashes from time to time. The best experience is accessing data locally, via your home network, using your own NAS.
Sharing libraries within Plex is very convenient. My friends manage the Plex Media Server and NAS. All I need to do is open the Plex app on my Apple TV and press play. To make local streaming a better experience, I’m willing to take an old laptop and install Plex Media Server on it. I’m sure my friends wouldn’t mind one less transcoding viewer on their servers. But, I can’t justify building my own NAS. And even if I had a NAS, I don’t want to manually copy a file from their computer to mine every time I want to watch something. The ideal experience is I open Plex, I see a movie that may or may not be on my local Plex Media Server, I click play, and it starts streaming from my local setup.
In this blog post I want to see if it’s possible to make streaming a shared library a great experience without the need for multi-terabyte storage array. To do this, we’re going to glue a few things together: IPFS and Plex.
Btw, this blog post is going to get very technical from here…
IPFS (Interplanetary File System)
The Protocol Labs team launched FileCoin as a way of using crypto currency to pay for storage that can be securely provided by any random computer in the world. It’s an interesting idea. Those folks building Filecoin needed a robust peer to peer storage system and built IPFS to fit their needs.
You can think of IPFS as Git meets Bittorrent. When you add a file to IPFS, you don’t pick the file name. IPFS looks take a hash of the content and will use that as its name. When you add a directory, the hash of the folder is made from combining the hash of its children. This process of chaining hashes is called a Merkle Tree, and it’s the same structure used to form a blockchain. IPFS is also like Bittorrent because it chunks a file into blocks and those blocks are made available for download by other peers in the the network (swarm). While Bittorrent creates a swarm for each torrent file, IPFS creates only creates one massive swarm, which serves any file available so long as someone has it added to their ipfs repository.
One implementation detail that is especially useful to us is how IPFS uses stores chunks of files. An IPFS repository has a built in file cache dataset. As you’re downloading files, IPFS stores those chunks into its dataset. This means that IPFS keeps recently accessed files from the network on disk. You can configure how much storage IPFS is permitted to use and how frequently it should garbage collect itself when it has exceeded the permitted amount.
For our use case, when we mount IPFS as a file-system (which you can do), and Plex begins to play a movie, IPFS will download and cache the blocks of the file that Plex needs to stream the content. IPFS is also supports seeking through chunks of a file. Meaning, when Plex starts playing, IPFS will download the first blocks of a file, but if we scrub to the middle of the movie, IPFS will begin downloading those new blocks right away, without needing all of the preceding blocks downloaded first.
IPFS ships with a built-in set of bootstrap nodes that anyone is welcome to use, making it a batteries included peer-to-peer network, but you can also create your own private swarm using your own custom bootstrap nodes. Since everything is content addressable, if you use the public network, someone else could see if you’re providing content whose hash matches that “linux iso” your friend is now sharing with you. With a private swarm, the entire network will only be made up of folks who have access to the swarm key and can talk to your bootstrap nodes. Might be worth doing. Even if you’re honestly only making personal copies of your own DVDs, that byte-for-byte backup might match what someone has shared on the internet for others to consume. Be safe out there.
A prototype
Now that we see how useful IPFS can be, let’s put the pieces together. We’ll have a consumer (me) watching a movie from a Plex server in one network (my house). In another network, there is a computer with a bunch of content (my friend’s computer at their house). The only way the Plex server at my house is connected to the file server at my friend’s house is via IPFS forming a private swarm. I started IPFS on the Plex server with the —mount flag which uses FUSE to mount /ipfs and /ipns directories for Plex to use.
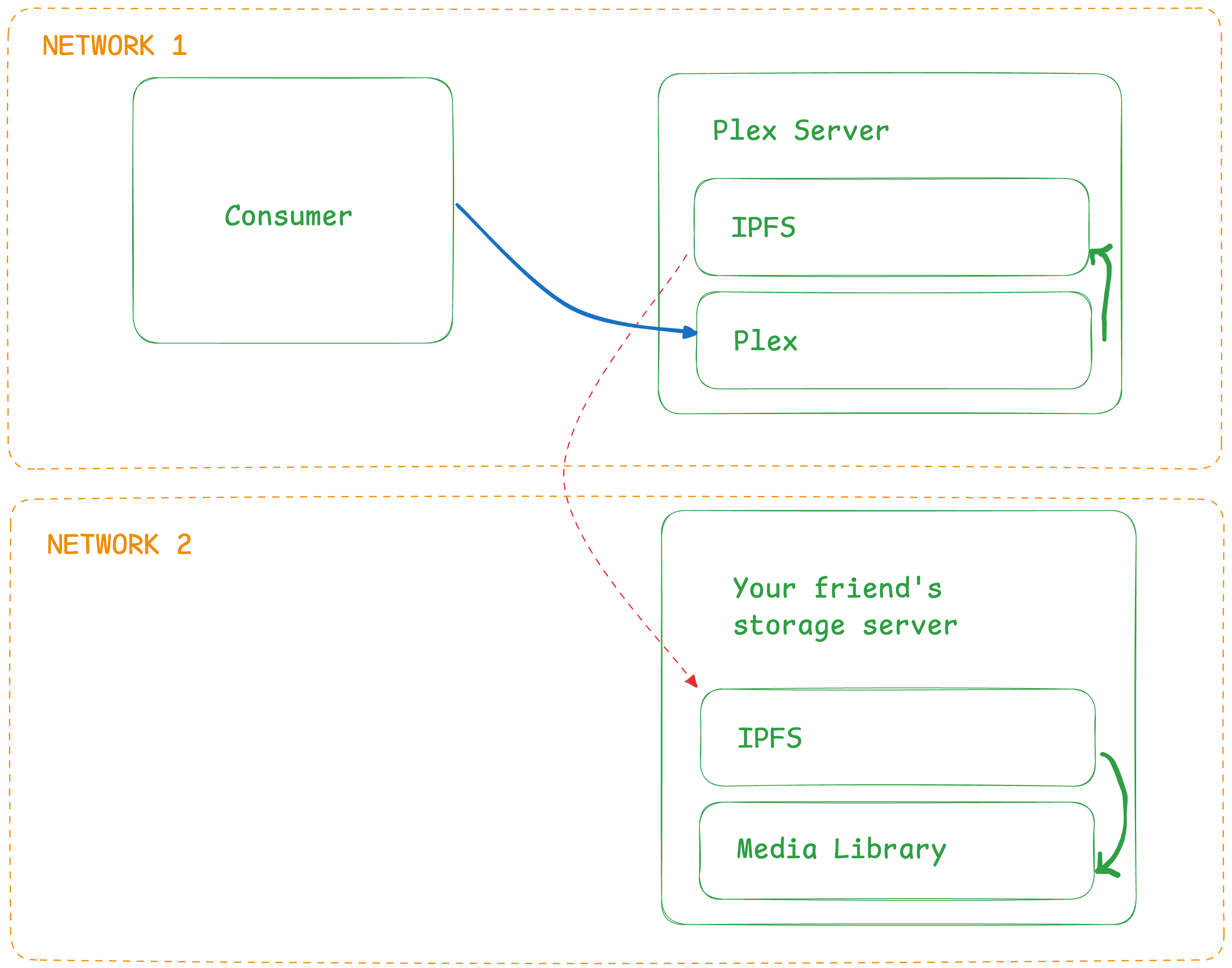
Let’s assume my friend has all of their content under a folder called media. They add their media folder to IPFS via “ipfs add -r media/” and it begins hashing their contents, ending with a final hash for the media/ folder.
ipfs add -r media/
added QmVLwGa84gVnNMrgZm6CvdW1KmPxVmmJBrMzXeW83qtUBH media/movies/4K60p.mov
...
added QmcoCpLhTuZe7wJvjysXX7iTjS8P7CKDasdx7Pr7GAqmY1 media/movies
added QmQPi8yv6TXWaCy25Bz2yTz6AvFDurgfZukAr5Pbuk5fjB mediaAt this point I can add a folder to my Plex media library via the hash of the media directory:
ipfs ls /ipfs/QmQPi8yv6TXWaCy25Bz2yTz6AvFDurgfZukAr5Pbuk5fjB/movies
QmVLwGa84gVnNMrgZm6CvdW1KmPxVmmJBrMzXeW83qtUBH 145719990 4K60p.movPlex will be able to scan the directory tree and look for content. It’s fairly simple. However, since the hash to the media directory is made by looking the hash of its children, as soon as we add another file, the media folder’s hash will change. Additionally, if we recursively run “ipfs add” when we have new files to add, it will need to recompute the hash of the entire directory. This might be fine the first time, but if you’re adding a multi-terabyte storage array, computing all of the hashes might take several days.
Fortunately, IPFS has work arounds to both of these problems. First, we’ll look at IPNS to create a pointer to the latest media folder hash, and then we’ll look at efficient ways to keep the media folder up to date.
A stable name for the shared volume
IPFS has a feature called IPNS (Interplanetary Name System) which works in a very similar way to DNS. Any node in the IPFS network can publish an IPNS record. These are broadcasted to the network (and rebroadcasted from time to time) so that folks listening can help build a database of other naming pointers. On my friend’s computer, we’ll publish a record pointing to their most recent media directory hash.
ipfs name publish /ipfs/QmQPi8yv6TXWaCy25Bz2yTz6AvFDurgfZukAr5Pbuk5fjB
Published to k51qzi5uqu5diu4kaslpvsbinit7t9srxamai7le2tlxgmsz0ahp5lgpc2p50c: /ipfs/QmQPi8yv6TXWaCy25Bz2yTz6AvFDurgfZukAr5Pbuk5fjBNow on my end, I can swap my library in Plex to look for content under /ipns/k51qzi5uqu5d(truncated)/movies . This way, as my friend adds files to his media server and updates the latest media hash, I will see it without any changes on my end. NOTE: If you don’t want to use IPNS, you can create a symbolic link to the /ipfs/<cid> of the media directory to /media/library (or something like that) so Plex has a stable path. Then, you can either manually update the symbolic link or find a way for your friend to publish and automate updating it on your end. Lots of ways to do this, but IPNS is built-in and easy enough to use.
Since this is a prototype I currently only have one royalty free video that I found online for the test file server that lives at my friend’s house. After syncing the /ipns/ path within Plex, it sees the file and created a thumbnail for it.
So what happens when you play a file? Plex and IPFS will cooperate in the following way:
Plex will begin to play a video by reading a chunk of it off disk.
IPFS will see that the file does not exist yet within its own cache and see if a peer in the network knows about this file. Since the file server at my friend’s house is part of the swarm, it will respond with data. Once those chunks are downloaded, it will return the bytes requested to Plex.
Plex will also begin transcoding if needed.
As Plex needs more data, it will open/read the file, IPFS will download more chunks, and Plex will continue streaming video.
I mentioned before that my friends would love to not have another real-time transcoding process run as I’m streaming video from their file servers. Plex may need to convert your file from the format on disk to either something it supports streaming (no Dobly TrueHD for example) or because the consumer watching the content is unable to stream at the original quality over the network. By default, Plex will transcode video as you watch, and this can use a LOT of CPU. One of the Plex transcoding quality settings is literally, “make my CPU hurt.” Ouch.

Btw, you can ask Plex to transcode once and store that file on disk so that it won’t need to transcode in real-time, but this means storing extra copies of your content on disk for the off chance that you need to stream Cinderella at 360p from your phone while on vacation. If you’re watching at home, you’re always going to watch it in its original version. Plus, the old laptop that I’ll be using later in this blog post was powerful enough to transcode a Blu-ray stream so long as I was the only one watching. I feel fortunate to have friends with very powerful servers at home that are capable of supporting many concurrent viewers.
Add files efficiently
As stated earlier, it’s super inefficient to recursively add your files every time you want to add a new piece of content to your library. Fortunately, you don’t have to. IPFS has something called MFS (Mutable File System) which is a pretend file system that exists within IPFS’s repo to make computing hashes really efficient. It looks like this:
# Recursively add your media the first time.
$ ipfs add --recursive media/
...
added QmZghJCEqj9wGFA4aJrWqqU4JvDJxyGBc1TdYV media/movies
added QmSQMJzLdU9ihqyj7WAEaqdF9Pm1otAA3o6WbK media
# Create your mutable file system
$ ipfs files cp /ipfs/QmSQMJzLdU9ihqyj7WAEaqdF9Pm1otAA3o6WbK /mediaThis tells IPFS MFS that a synthetic folder named /media will point to the most recent hash of friend’s very real media/ directory. No bytes are actually copied from the real media directory when we do this, because the synthetic /media directory doesn’t actually exist in a usable form on disk. It lives within the IPFS repo and is modified by using additional “ipfs files” commands.
Let’s say my friend backup up a new DVD he bought at the Goodwill. They copy it to their media server at the path media/movies/next_movie.mp4. To add it to IPFS, they will need to use “ipfs add” like before, but this time without the recursive flag. This time they only add the one single file. After IPFS outputs a hash of the new movie, the ipfs files commands can be used to “copy” it into our MFS.
# Add the file to IPFS
ipfs add media/movies/next_movie.mp4
added QmYabpsDGpJnWEL7ZE media/movies/next_movie.mp4
# Add the file to your IPFS MFS
ipfs files cp /ipfs/QmYabpsDGpJnWEL7ZE /media/movies/next_movie.mp4Now we can check the hash of the /media directory in our MFS, and we’ll see it changed. MFS automatically recomputed the hashes in the Merkle Tree when the new file was added. MFS keeps a reference to the hashes of the files in our synthetic /media directory, making it possible to recompute the parent folder hash efficiently.
# Now you can get the updated hash of the /media directory
$ ipfs files stat /media --hash
QmZvUQTjbB8yVibnGuXYTb2a6aArubDHwjG57WdUkdVqnNAnd finally, since we’re using IPNS to keep track of the latest media/ directory, my friend updates their IPNS by using the same command above to find the new root hash of their synthetic /media directory.
# Add the file (more concise)
ipfs add media/movies/thing.mp4 --to-files /media/movies/
# Update IPNS
ipfs name publish "/ipfs/$(ipfs files stat /media --hash)"Since IPNS is like DNS, my computer sees the old media directory for a while until caches invalidate. Once they do, Plex will see the latest directory structure. IPFS has many configuration options with reasonable defaults for a public network, but you may want faster cache refreshing in your private swarm. The IPFS configuration docs cover this quite thoroughly.
Why is this more efficient? Instead of recomputing the hash of the entire media server like we had to the first time we added all the files, we only paid the cost to hash one file and then recompute the directory hashes. On the cheap VMs I’m using to build this prototype, IPFS takes about 10 seconds to hash 1GB of data. This means a 25GB Blu-ray might take ~4 minutes for IPFS to compute its hash. I think this is reasonable amount of time to add a single file, but you may disagree.
Warming the IPFS datastore cache
As mentioned, when Plex is playing back content, the player opens and reads only the part of the file that the end user is watching/ buffering. IPFS will see the next chunk of the file is unavailable and download it from a peer in the network. This works fairly well, but I worry about latency should a peer not be immediately available. To improve this, we can proactively ask IPFS to download all the chunks of the file outside of Plex. I tried to implement this a few ways before finding a solution that worked.
I first tried using a filesystem notifier to detect when any process performed a “stat” or “open” from a file under the mounted /ipns/ FUSE volume on my Plex server. While very simple, this ended up straining the IPFS daemon a lot. I didn’t find a root cause as to why this is, but given we’re going from FUSE to IPFS, I figure a user space filesystem isn’t really equipped to handle this use case. If someone knows how to do this without maxing out CPU across all my cores, please let me know.
Next up, I looked into the webhook feature built-in to Plex. This did not prove fruitful though, because 1) to use the feature, you need to subscribe to the Plex Pass subscription, which I don’t have, and 2) the content of the webhook provides Plex specific information, meaning it doesn’t actually provide information about the name or path of the file being accessed.
Finally, after verifying that stat and open were the syscalls Plex was using via strace, I wrote a simple eBPF script to very efficiently observe what Plex and its children were accessing. When I detect a file from the mounted /ipns/ volume being accessed, I spawn a subprocess that runs “ipfs refs -r $filename” and IPFS starts downloading all the chunks of the file.
Remember, none of this caching warming is necessary, but if I’m watching a very large movie, I’d prefer the data be eagerly loaded to ensure the best experience.
// Relevant snipped of my eBPF tracer
#include <uapi/linux/ptrace.h>
#include <linux/fs.h>
#include <linux/sched.h>
struct data_t {
u32 pid;
char filename[256];
char comm[TASK_COMM_LEN];
};
BPF_PERF_OUTPUT(events);
int trace_open(struct pt_regs *ctx, const char __user *filename, int flags) {
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid() >> 32;
bpf_get_current_comm(&data.comm, sizeof(data.comm));
bpf_probe_read_user_str(&data.filename, sizeof(data.filename), filename);
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}For those copying the above, be careful! Plex might be using stat/open to generate a thumbnail. If you bundle this with the bcc python package, you might want to wait for ~5 open calls within a 5 minute window before preloading the file. This is clearly a nice-to-have feature, so breadcrumbs are all I’m leaving you with.
Bring on the Blu-ray
At this point my test Plex server is working, I’m able to access the library on-demand from my friend’s house, and I’m able to eagerly download media when I start playing video in Plex. Testing with a 500MB 4k sample video is one thing, but now we’ll see if a true Blu-ray video can stream over IPFS without any hiccups. Keep in mind it was my frustrating experience with Blu-ray streaming that kick-started this whole experiment.
To begin, I fired up that old laptop running in my house for reals, mounted configured ipfs to the existing private swarm, and installed a fresh copy of Plex. I uploaded a real fair-use 30GB Blu-ray video to the VM in the cloud acting as my friend’s house, asked Plex to check for media. The file almost immediately showed up and I clicked play. It worked!… mostly!
The video began streaming almost immediately, which is excellent. IPFS was able to keep up with the video chunks as fast as Plex requested them. Having IPFS load the remaining chunks into its datastore worked too. The only issue I experienced was scrubbing through the video. I was starting to hit some IPFS throughput limits which I’ll tackle in a minute. The blips were either a short window of buffering while streaming or a ~10 second buffer delay before content resumed playing after scrubbing well passed what Plex had already loaded or IPFS had downloaded.
I then turned off my cache warming script and asked ipfs to delete any blocks it had downloaded prior to a retest. I also restarted Plex just to make sure no media streaming processes stuck in a state waiting on the IPFS volume mount. Blu-ray video began streaming just fine, and scrubbing 25% through the video only took ~2 seconds before playback resumed. Very impressive.
The experience was significantly better than scrubbing Blu-ray videos, served from spinning disks at my friend’s house, peering over residential ISPs, from different cities. Like, scrubbing Blu-ray (once cached) with <0.5 second buffering time put a huge smile on my face. Still, further optimizations are required because IPFS was starting to hit its upper-bound of network throughput.
Optimizing IPFS as much as possible…
The default configurations of IPFS are tuned for a healthy balance between network health and performance. Given we’re operating within our own private swarm, I wanted to see if we could increase network throughput. I’ve been using two cloud VMs with SSDs for my prototype thus far (other than when I broke out my laptop for real-world testing). The VMs are in the same general region but in different data centers. I used the same 30GB Blu-ray used perviously to send between nodes.
My baseline throughput before tweaking any settings between two cloud VMs was ~100mbps. This matches what I was seeing on the laptop running plex at home. This isn’t terrible, but it is far from ideal. For comparison, a straight TCP transfer between the VMs was ~1.6Gbps.
I saw a marginal (slightly above noise) performance improvement by increasing the bitswap engine workers and task count. The only real measurable increase I found was via increasing playing with MaxOutstandingBytesPerPeer. I started at 1MiB and increased it to 10GiB. At 10GiB the transfer throughput was ~250mbps, so 2.5x above baseline. This is a usable network speed for the Plex use case, but still 6.4x slower than the raw TCP copy between nodes.
"Internal": {
"Bitswap": {
"EngineBlockstoreWorkerCount": 2500,
"EngineTaskWorkerCount": 1024,
"MaxOutstandingBytesPerPeer": 10000000000,
"TaskWorkerCount": 1024
}
}Looking at my node metrics, the node downloading the file was showing ~20% iowait via iostat. To remove this as a bottleneck I provisioned a larger VM with ~64GB ram and a much much nicer NVMe and repeated the bench test. The new VM was able to download the 30GB file at around ~1Gbps. Significantly faster.
There are many knobs you can twist and turn within IPFS, including the block side of the file when you add it to IPFS; however, I didn’t see any real improvements other than what I posted above, and the real winner was upgrading my VM to better hardware. IPFS clearly isn’t capable of competing with proxies like nginx or varnish which serve most of the worlds CDN needs. But, to avoid sounding like a cynic, I think what the IPFS teams has achieved is incredibly impressive. The “cheap” VMs were already operating just fast enough to stream and scrub Blu-ray video, so seeing a possible 4x performance gain with better hardware makes me better knowing things will improve when I eventually upcycle my current laptop to become my next-gen media server.
Present status
With these new optimizations, and a tuned cache warming script, etc.. it’s still very very good but still not perfect. I experience maybe one or two blips while streaming Blu-ray content, but it’s a dramatically better experience to what I was using before. And just to pause for a second to remember… streaming a 15GB/hour video is a legit stress test. Analyzing the library I have access to, only about 5% has a data rate close to my 30GB Blu-ray file. Everything below Blu-ray works flawlessly.
So what’s next? Well, Plex on top of IPFS appears to work well enough to warrant further experimentation. Next steps are adding the full 60TB library of content to my private swarm and settle in for long term usage. I hope IPFS will continue to be stable serving that much data over residential ISPs.
Etc.
If you’ve made it this far, you must be interested in doing something similar… and you should! Peer to peer networks are about as punk rock as you can get in the field of computing. And like punk rock, you must acquire a taste for it. Networking issues are difficult to debug. Distributed networks running, served from computers at home, are 100x harder to debug. But that shouldn’t stop you from playing with the tech and seeing how far you can take it.
Plus, there are many many distributed file system projects out there to play with. I found that most are open but freemium versions of a commercial product, which is great for support, but it’s not something I really want to use knowing the community is fueled by venture funding. Maybe IPFS isn’t too different given it was built for Filecoin, but at this point, the IPFS community is larger than its parent project.
Conclusion
Do I honestly expect folks to go out and start installing IPFS to share content with their friends? No way. But I bet either you or someone in your friend group has already achieved 90% of this on their own. I know I’m a nerd but 1 in 5 friends I polled have some sort of media server setup at home that they use, and I would like to see them share their libraries with other friends the way friends lend tools or a cup of sugar.
Furthermore, I think there is a LOT of interesting applications for private peer to peer networks. I know it’s so fashionably Web3 to make decentralized everything happen, but for items like your media, which bring their own gray area of copyright concerns, it’s best to keep that kind of sharing between folks you actually know.
Maybe you don’t quite feel like streaming subscription are unbearable enough to build one yourself. I don’t feel enraged enough to leave them entirely, but I do feel like I’m getting closer with each passing day. Hopefully in this blog post you see a way to connect with friends who have gone through the effort to make their own own personal media server and together build your own sharing economy.
✌️
P.S. If you’re working on making private peer to peer networks a thing, please reach out! I want to play with it. I think I have a pretty compelling use case ;).
P.S.S. Yes. Streaming Blu-ray movies is really that good. You should try it but don’t be surprised when it spoils your appetite for anything else.